
Jordan Myers
myers.jordan.d AT gmail DOT com
Welcome to the personal website, portfolio, and blog for Jordan Myers!
Syllabifying toki pona with a Regular Expression
A quick regular language approach to syllabification of the constructed language toki pona.
by Jordan Myers
 ni li ilo Lekula Epesen. Literally “this is tool Regular Expression”. Written in sitelen sitelen, a fun nonlinear writing style developed by Jonathan Gabel.
ni li ilo Lekula Epesen. Literally “this is tool Regular Expression”. Written in sitelen sitelen, a fun nonlinear writing style developed by Jonathan Gabel.
Hello everyone! Recently, the minimalist conlang toki pona has captured my interest. For those who are unaware, toki pona is a constructed-language created by Sonja Lang with the purpose of allowing one to reduce the clutter of their mind down to a few essential semantic building blocks. It’s surprisingly simple to pick up while remaining robust enough to cover a variety of general conversation. I would recommend reading pu, the official book for those interested.
Syllabification is the process of breaking up a word into syllables, a typically very easy task for native speakers of a language, but nonetheless a task that is much more difficult to formalize.
Take for example the English word banana.
I’m sure many of you would agree that banana is made up of three syllables, but where would you draw the boundaries? Do you split it up like ba . na . na, or perhaps would you opt to include the n as the coda (final position) of the syllables as such: ban . an . a. Or perhaps ba . nan . a. I think that many would agree that the second and third syllabifications are clunky, but why? Without diving too far into phonology, most would agree that speakers elect the syllabification of ba.na.na because it follows the maximal onset principle. This states that consonants between vowels should be assigned to the initial position of the syllable as long as they conform with the rest of the specific language’s phonotactics (the rules for how sequences of sound are allowed to be arranged).
So to begin with toki pona, we need a way to understand the syllable structure and phonotactics of toki pona. So I’ve prepared this chart:
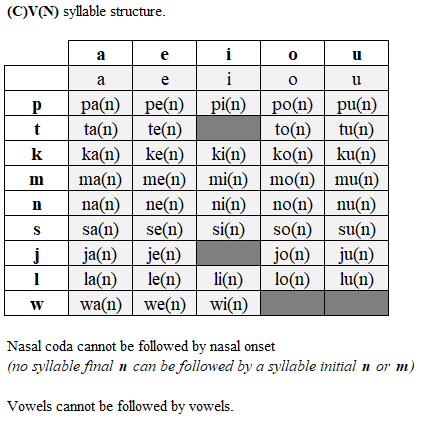
This table was created with knowledge of the official book as well as supplemental knowledge from: https://devurandom.xyz/tokipona/7a.html
As a brief aside, when written in latin characters, toki pona essentially follows the pronunciation prescribed by the IPA (international phonetic alphabet). Therefore [aeiou] all sound as they would in Spanish or Japanese, while the [j] is pronounced like a y would sound in English.
This chart covers all the segmental features of toki pona. There are additional suprasegmental features like stress and intonation. Stress in toki pona always occurs on the initial syllable, and there are no hard prescribed rules around intonation (other than maybe rising intonation for questions).
To the uninitiated, this could seem like a lot, however this is an astoundingly brief piece of information that covers the totality of the prescribed phonotactics of toki pona. Due to toki pona’s minimalist phonology, I thought it could be appropriate and possible to tackle the issue of syllabification with a simple regular expression. If I could, that would show that the syllabification process in toki pona can be described as regular language.
I posit that a human language (constructed or otherwise) with phonotactics that follow a simple regular language reduce the cognitive workload on individuals attempting to acquire the language and allow for quicker acquisition.
I will not be able to prove this argument true in this article, but instead will show you the inner mechanics of the regular expression approach I’ve taken to syllabification while maintaining the position that this can be a fruitful area of further research.
ni li ilo Lekula Epesen. ilo ni li ken lanpan e nimi wan ale pi toki pona.
This is the regular expression. This tool can capture all the syllables of toki pona.
# Note this regular expression is running with global, case-insensitive, and extended (ignore whitespace) flags.
[ptkmnlswj]?
(?:(?<=w)[aei]|
(?<=[jt])[aeou]|
(?<=[pkmnls])[aeiou]|
(?<=\b)[aeiou])
(?:n(?![nm]?[aeiou]))?
kin, sina wile lanpan e nimi ale la sina ken kepeken e ni:
Additionally, if you want to capture whole words, you can use this:
# Note this regular expression is running with global, case-insensitive, and extended (ignore whitespace) flags.
\b(?:[ptkmnlswj]?
(?:(?<=w)[aei]|
(?<=[jt])[aeou]|
(?<=[pkmnls])[aeiou]|
(?<=\b)[aeiou])
(?:n(?![nm]?[aeiou]))?)+\b
All individual syllables captured by the regular expression:
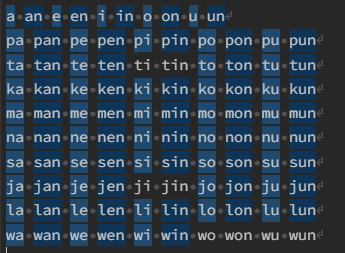
These regular expressions contain no backreferences, and therefore can be modeled with finite state machines.
Let’s break the regular expression down into three components:
The onset:
[ptkmnlswj]?
The onset is simple. It consists of an optional consonant from the complete inventory of consonants in toki pona.
The nucleus:
(?:(?<=w)[aei]|
(?<=[jt])[aeou]|
(?<=[pkmnls])[aeiou]|
(?<=\b)[aeiou])
The nucleus is a bit more complex. Here I have a non-capturing group of four different possibilities. Each of the four routes we could go down starts with a positive lookbehind:
- If we started with a w then only a, e, or i can follow.
- If we started with j or t, then only a, e, o, or u can follow.
- If we started with any of the other consonants, any of the vowels can follow.
- If we started with a word boundary (we omitted the onset), then any of the vowels can follow.
The coda:
(?:n(?![nm]?[aeiou]))?
The coda is probably the most complex part. Here I have another non capturing group, but this one is optional. The expression here states to capture an n, but then a negative lookahead follows. The negative lookahead will cause the n coda to fail to capture if what follows afterward is one of the following:
- n and then any vowel
- m and then any vowel
- any vowel
This ensures that words like nanpa are correctly syllabified as nan . pa, but an invalid word like nanma will fail to syllabify. The segments na and ma will be captured, but the middle n will not be. This means that the tokenization version of the regular expression will also fail to capture the whole invalid word, which is desirable.
This abstraction of the syllabification process is not without its warrants.
Primarily, this process is applying to textual phonetic data (since all the symbols in toki pona’s latin orthography are pronounced only one way). This regularity allows for a description of the syllabification process to be done with a regular expression, although the computation for this specific process applies more towards the case for learning to read and parse toki pona, rather than syllabify utterances phonologically. However, the two cases of listening/phonological comprehension and reading/lexical comprehension are thought to be related.
Secondarily, as a constructed language, toki pona has the benefit of containing no phonetic irregularity whatsoever. This is not the case for many natural languages. The true insight from this work will come with further research comparing toki pona to natural languages.
tags: syllables - phonology - toki-pona - regular-expressions